Manipulation
主要问题
- 物体的表征(representation)?根据具体任务有所不同
- 刚体:
- 重排列任务:空间关系?
- 3D deformable object
- 塑形任务
- 打包装箱任务
- 2D deformable object
- 叠衣服:2D的拓扑表征是什么?
- 1D deformable object
- 绳结:knot theory的拓扑
- 几何模型
- 刚体:
2024
HACMan++: Spatially-Grounded Motion Primitives for Manipulation
Bowen Jiang et al., CMU RSS2024
- 什么是Spatially-Grounded motion primitives?
- what:primitive类型,如grasp或push
- where:在哪里发生(spatially-grounded),如gripper在哪里产生接触
- how:如何执行?如应该向那个方向推或grasp orientation(将primitive参数化)
Interactive Robot-Environment Self-Calibration via Compliant Exploratory Actions
Podshara Chanrungmaneekul et al., Rice, IROS 2024
- 主要贡献:不需要额外传感器,只通过机械臂末端主动与环境进行touching和sliding的交互,获取contact信息,校正自身的坐标系信息
identifying the robot-environment spatial parametersself-calibration问题estimating the pose of a robot manipulator in an uncalibrated environment without the requirements of any external sensors such as cameras(an accurate pose of the robot frame relative to a frame of the workspace) - 通过touching和sliding动作主动的与环境交互,使用Particle Filter对robot-environment (环境为静态的)的空间关系进行建模
- 存在的问题:
- 扩展到矫正更多的传感器,如相机
Discovering Predictive Relational Object Symbols With Symbolic Attentive Layers
Alper Ahmetoglu et al., Bogazici University, IROS 2024
- 主要贡献
- relational object symbols是什么?
compute discrete selfattention weights from object features and treat them as relational symbols between objects
- relational object symbols是什么?
- 存在的问题
- Relational DeepSym,输出多个物体间的关系
- 用self-attention mechanism架构,提取relational symbols between objects,将关系离散化
- 输入为一系列物体特征(状态向量
),包括物体类型(如short block,long block)及其位姿(位置 和欧拉角 ),共8个维度,方法可扩展到更多不同类型的输入 - high-level action为pick-place(
) Δyi and Δyj are the y-axis pick and release positions relative to the center of the object (Fig. 2(a)). Δyi and Δyj can take discrete values of {−1, 0, 1} which correspond to 7.5 cm left, center, and 7.5 cm right of the object center, respectively。总计
种 - 状态描述符,目的是将状态向量
转化成描述物体的特征向量 和关系符号 ,第k种关系 The goal is to transform the state vector O = {o1, … , on} where each oi ∈ Rdo is a feature vector describing object i into a set of object symbols Z = {z1, … , zn} and relational symbols Rk = {r(k) 11 , … , r(nkn)} where zi ∈ {0, 1}dz is a dz-dimensional binary vector (i.e., an object symbol) for the ith object and r(k) ij ∈ {0, 1} is a binary value for the kth relation between the ith and jth objects.
2023
CALAMARI: Contact-Aware and Language conditioned spatial Action MApping for contact-RIch manipulation
Youngsun Wi et atl., UMich, CoRL 2023
- 主要贡献:
language-conditioned and contact-aware spatial action map representationlanguage guide manipulation(任务是诸如wipe_desk,sweep_to_dustpan,push_button)- MPPI控制器算法预测接触目标和接触constraint
- 无需fine-tuning即可泛化至未见过的物体
- 实现方法:
generate word-wise heatmaps that high light the spatial locations in the RGB images corresponding to specific words in the language instruction
SpaTiaL: monitoring and planning of robotic tasks using spatio-temporal logic specifications
Christian Pek et al., TUdelft, Autonomous robots 2023
2022
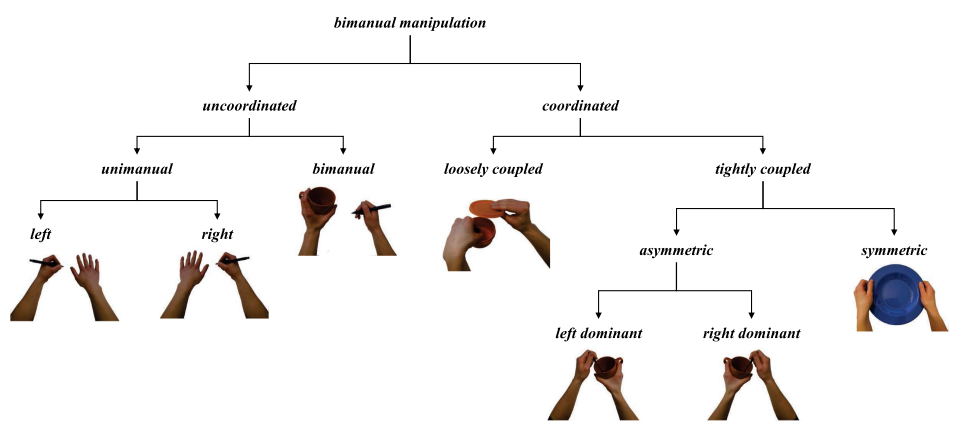
A Bimanual Manipulation Taxonomy
Franziska Krebs et al., H2T KIT (Tamim Asfour), RAL 2022
A General Method for Autonomous Assembly of Arbitrary Parts in the Presence of Uncertainty
Shichen Cao et al., IROS 2022
Human-Like Multimodal Perception and Purposeful Manipulation for Deformable Objects
Upinder Kaur et al., Purdue, CASE 2022
- 2D object (ziplock bag)
StructFormer: Learning Spatial Structure for Language-Guided Semantic Rearrangement of Novel Objects
Weiyu Liu et al., UW, ICRA 2022
- 主要贡献
- 实现对物体的重新排列任务。输入为点云,通过transformer神经网络,目标为给定的排列方式指令(结构化语言)
we propose a novel transformer-based neural network, StructFormer, which takes as input a partial-view point cloud of the current object arrangement and a structured language command encoding the desired object configuration. enables a physical robot to rearrange novel objects into semantically meaningful structures with multi-object relational constraints inferred from the language command.
- 实现对物体的重新排列任务。输入为点云,通过transformer神经网络,目标为给定的排列方式指令(结构化语言)
- 实现方法:
- 架构:transformer
- 训练数据量:100,000个序列,其中80%用于训练
We introduce a dataset for four representative structures containing more than 100,000 rearrangement sequences in total.We split the dataset into 80% training, 10% validation, and 10% testing.
- 存在的问题:
- 直接通过自然语言,而不是结构化语言指定目标结构
- 未解决
placement in clutter或finding the optimal order of rearranging actions,排列顺序为预先给定build in a predefined order - 不同场景,不限于桌面
- 具体细节
- Transformer的作用:encoder接受语言输入,decoder预测应该执行的运动
The encoders can directly predict what objects to move and also provide a context for an autoregressive transformer decoder to predict where the objects should go and how they should be oriented. - structured language command是什么样的?
- 范例”“Rearrange objects that have the same class as the yellow object into a circle””
The language instructions involve many different semantic and geometric properties for both grounding objects and specifying the spatial structures.其中 为word tokens We map each unique word token from the language instructions to an embedding with a learned mapping $h_w(w_i) -> c_i$
- Transformer的作用:encoder接受语言输入,decoder预测应该执行的运动
2021
SORNet: Spatial Object-Centric Representations for Sequential Manipulation
Wentao Yuan et al., UW, CoRL 2021
- 主要贡献:
- extracting object-centric embeddings from RGB images that generalizes zero-shot to different number and type of objects
- 获取物体的空间关系,仅依赖logical supervison
a framework for learning object embeddings that capture continuous spatial relations with only logical supervi sion - 数据库
- 此外在测试任务包括空间关系的问答
- 实现方法:
- 使用Visual Transformer
- 输出top、on_surface、stacked、aligned等
- 在真实环境中测试了open loop planning
- 存在的问题
2013
Robotic surface assembly via contact state transitions
Amar Saric et al., UNCC, CASE 2013